Resampling Methods — A Simple Introduction to The Bootstrap Method
Intuition, motivation, and how it works on the bootstrap method

Introduction
In statistics, the bootstrap is a widely applicable and extremely powerful statistical tool that can be used to quantify the uncertainty associated with a given estimator or statistical learning method.[1] The bootstrap can derive a strong estimate of a population parameter such as standard deviation, mean, median, standard error, etc.
In wikipedia — the bootstrap is statistical method for estimating the sampling distribution of an estimator by sampling with replacement from the original sample, most often with the purpose of deriving robust estimates of standard errors and confidence intervals of a population parameter like a mean, median, proportion, odds ratio, correlation coefficient or regression coefficient.
Motivation - why we need to strong estimate population parameter
When we go to market to research the average price of sugar, we have a sample data price of sugar from several stores, price = (price-1, price-2, price-3,. ., price-N) and from that data we have the average price of sugar is U. there is one question : How far is the consistency of the average price ? How far is the consistency of the standard error? the question can be answered by the bootstrap method
Intuition — How does the bootstrap method estimate a population parameter ?
In this section we illustrate the bootstrap on a price of sugar in which we wish to determine the best mean. This illustration uses 10 “dummy” data, this is only an example because in real cases 10 samples are not enough to bootstrap.

Just looking at the figure 1, there are several new populations (blue boxes) that refer to the original population. If we analyze the process of forming a new population, each item drawn from the sample space is replaced back into the sample space. Hence the sample space remains the same for all the items drawn from it, this process is called the sampling with replacement method.
every new population formation, the resulting population parameters are recorded. In this case, the results of the first population parameter yield mean 4.11, the second population parameter yield mean 5.55, this process is repeated until it has a strong estimate of a population parameter.
Generally, bootstrap involves the following steps:
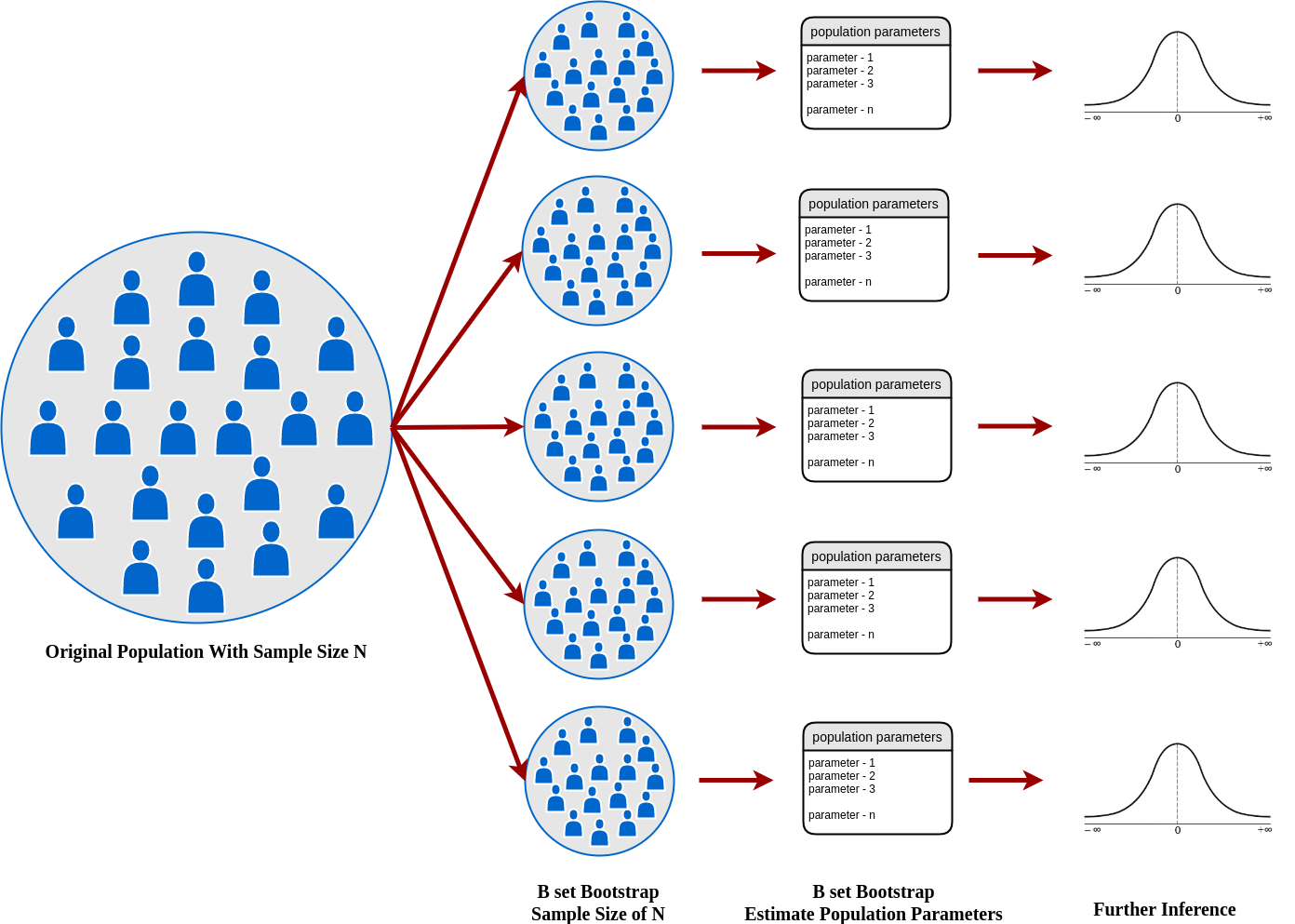
- Original Population With Sample Size N — A sample from population with sample size N.
- B set Bootstrap Sample Size of N — Create a random sample with replacement from the original sample with sample size N as the original sample, replicate B time, and there will totally B Bootstrap Samples
- B set Bootstrap Estimate Population Parameters — evaluate the resulting of population parameters
- Further Inference — strong estimate of population parameters such as mean, standard error, confidence interval, etc.
Notes of The Bootstrap Method
- The bootstrap method is not a way to reduce errors, but only tries to estimate errors.
- The bootstrap distribution usually estimates the shape, spread, and bias of the actual sampling distribution.
- The bootstrap process does not replace or add new data.
- Bootstrapping cannot be done when :
- The data are so small that they do not approach values in the population
- The data has many outliers
- Time series data, the bootstrap is based on the assumption of data independence

Continue Learning — How Bootstrap Method work in Machine Learning
Implementation of Bootstrap Method in Machine Learning : A Simple Introduction to The Random Forest Method
About Me
I’m a Data Scientist, Focus on Machine Learning and Deep Learning. You can reach me from Medium and Linkedin
My Website : https://komuternak.com/
Reference
- Introduction to Statistical Learning
- Wikipedia — Bootstrapping (statistics)
- Widhiarso, Whayu. Introduce to the bootstrap
- Yen, Lorna. An Introduction to the Bootstrap Method
